Levenshtein Distance又称编辑距离,是衡量两段字符的差异大小的一种方法,也可以看做从一个字符串转换到另一个字符串所需要的最少的操作数,并以此计算相似度。听说应用于拼写检查、论文查重、dna基因序列分析等,当然我没有这种用途,我在工作中因为需要预测bug,则需要匹配条件和匹配输出信息来确定是不是已有bug,于是用到了这种算法。之前也写过两篇关于机器学习的算法,就是用于预测错误类型的。
对于字符串检查,则有三种操作:插入、删除、替换。每一种每一次代表了操作数加一。
对于编辑距离算法,有个图描述了公式和条件。如下图。当然理解起来不方便,我也贴了其他图描述这个过程。
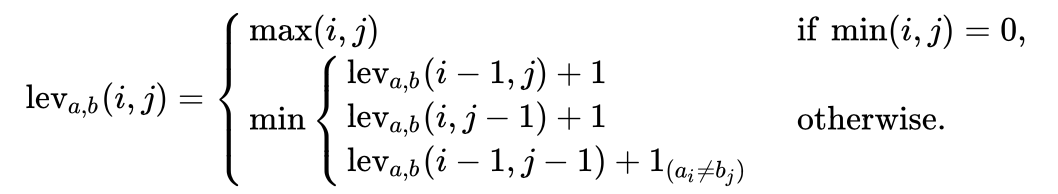
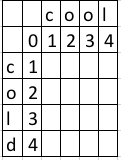
比如比较cool和cold两个单词的相似程度和计算操作数。下图是初始化一个表,并给予每个字符一个序号。
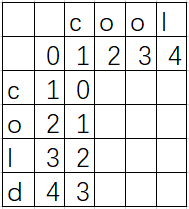
对于每一行每一列的一个位置,都会对应着两个字符串的两个字符,我们分别查看左边的值+1,上边的值+1,以及左上的值(相同则为加0,否则加1)。
取这三个值的最小值。比如这个图可以演变为:
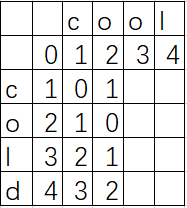
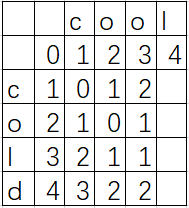
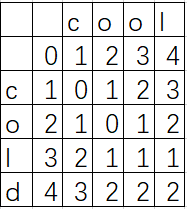
每一个位置代表当前需要的操作数,比如'coo'与'col'的操作数为1。右下角的数字则为这两个字符串的操作数,即为2.
相似度的计算公式则是1-(levenstein/max_length)或者(max_length-levenstein)/max_length,比如'cool'与'cold'的相似度为50%。
肯定实际工作使用中不会有这么简单的情况,但原理差不多。对于python的话,还有个包可以帮助计算:fuzzywuzzy。
以下是python代码,用于计算操作数的简单样例:
import numpy as np
def edit_distance(word1, word2):
len1 = len(word1)
len2 = len(word2)
dp = np.zeros((len1 + 1, len2 + 1))
for i in range(len1 + 1):
dp[i][0] = i
for j in range(len2 + 1):
dp[0][j] = j
for i in range(1, len1 + 1):
for j in range(1, len2 + 1):
delta = 0 if word1[i - 1] == word2[j - 1] else 1
dp[i][j] = min(dp[i - 1][j - 1] + delta, min(dp[i - 1][j] + 1, dp[i][j - 1] + 1))
print(dp)
return dp[len1][len2]
print(edit_distance("horse", "rose"))
文章评论 (0)