最近邻算法(k-Nearest Neighbor,KNN)或许是机器学习算法中最简单最容易理解的一种。它的思路是通过已被标注过的数据集,来判断新数据的类别,数据集的特征值是可以量化的,并且是有明确的标签,通过计算距离来选取K个跟新数据最近的数据,用最多的类型来确定新数据的类型。
类似下面这张从bing搜索出来的图所示:
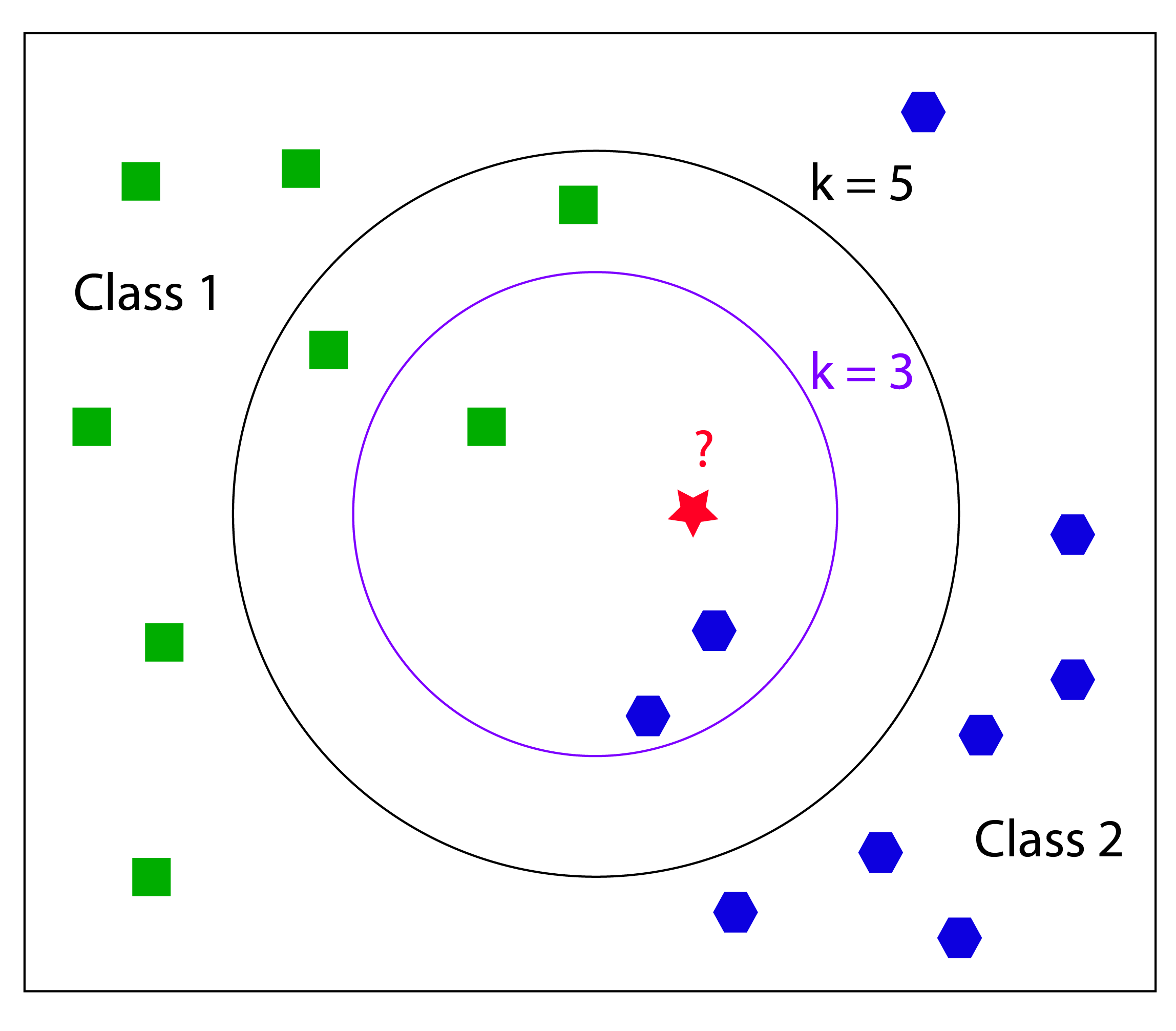
KNN是需要历史数据的,越多越详细那么判断就会越准确。数据集的特征值需要量化,或者可以转换(比如独热编码)。新数据会由它的特征值来计算它本身的位置,那么周围最近的已知数据则能描述它可能的类型。可以理解为物以类聚人以群分。(当然对于一些特殊数据,就像椰子树长在高纬度,虽然有可能,但是KNN对这种的就显得比较无力)
优点:精度高,对异常值不敏感,无数据输入假定。
缺点:计算复杂度高,空间复杂度高
适用数据范围:数值型和标称型
比如我想判断一个程序运行后的错误类型。先载入数据:
# environment, browser, pass_rate, duration, error_type
import pandas as pd
import os
file_path = os.path.join(os.getcwd(), "data", "execution_history.csv")
history_data = pd.read_csv(file_path)
labels = history_data["error_type"]
对于environment, browser这种文本型数据,可以将其转换为数据型。对于互斥型,比如男性或者女性,这种可以用0和1来代替;对于有序关系的比如尺寸大小的,可以用1,2,3之类代替。对于平级的离散的数据,可以采用独热编码(on-hot encoding), 意思是使用N位状态寄存器来对N个状态进行编码。(但是,如果这种平级的离散数据类别太多,比如街道名,那么可以出现上万乃至上百万的编码,创建如此大的二元向量并不是一个好的方法,因为会很低效,在处理这些向量时会占用大量的存储空间并耗费很长的计算时间。在这样的情况下可以使用稀疏表示法,即仅存储非零的值,并仍然为每个特征值学习独立的模型权重。稀疏表示法的解释可以参考:稀疏表示法)
# covert environment and browser
history_data = pd.get_dummies(history_data, columns=['env'], prefix_sep='_')
history_data = pd.get_dummies(history_data, columns=['browser'], prefix_sep='_')
这里又会出现另一个需要注意的地方。当browser之类被转换为数值,则会是0,1之类。对于duration这种数据,可能是几百秒甚至更大的数字,在计算距离时,duration就会起到决定性的作用,但是实际情况duration和其他条件是共同影响结果的,是平级的判断标准,因此这里需要将duration做归一化处理。
# normalize duration
# (x-min)/(max-min)
min_duration = history_data["duration"].min()
max_duration = history_data["duration"].max()
if min_duration == max_duration:
history_data["new_duration"] = history_data["duration"].apply(lambda x: 1)
else:
history_data["new_duration"] = history_data["duration"].apply(lambda x: (x-min_duration)/(max_duration - min_duration))
计算距离并选择K个最近目标出现次数最多的类型:
# load new data and compute
# distance formula: ((x1-x2)**2+(y1-y2)**2+...)**0.5
new_data = pd.read_csv(os.path.join(os.getcwd(), "data", "new_data.csv"))
# convert data as well
new_data = pd.get_dummies(new_data, columns=['env'], prefix_sep='_')
new_data = pd.get_dummies(new_data, columns=['browser'], prefix_sep='_')
min_duration = new_data["duration"].min()
max_duration = new_data["duration"].max()
if min_duration == max_duration:
new_data["new_duration"] = new_data["duration"].apply(lambda x: 1)
else:
new_data["new_duration"] = new_data["duration"].apply(lambda x: (x-min_duration)/(max_duration - min_duration))
new_data.drop(columns=["duration"], inplace=True)
# check the nearest 3 data
knn_columns = new_data.columns.values
for seq in range(len(new_data)):
error = new_data.iloc[seq]
for index, row in history_data.iterrows():
sum = 0
for column in knn_columns:
sum += math.pow(getattr(row, column) - error[column], 2)
distance.append(math.sqrt(sum))
history_data.loc[index, "distance"] = math.sqrt(sum)
history_data = history_data.sort_values(by=["distance"])
predict_top = history_data.iloc[:3]["error_type"]
new_data.loc[seq, "predict_error"] = pd.value_counts(predict_top).index[0]
new_data.to_csv(os.path.join(os.getcwd(), "data", "new_data_predict.csv"))
然后在新文件new_data_predict.csv中就可以看到结果了。
文章评论 (0)