前些时候公司给每个人都配备了Github Copilot,经过公司内一系列账户和权限的折腾,终于可以用起来了,至少不用像以前用个LLM就被警告了,这下总能满足安全需要了嘛。
在vs code和pycharm里都配置了copilot,用起来还行,能补全文档和代码,能解释代码,能生成代码,虽然还是需要自己审核一下,不过也算省了一些事。
不过问题也来了,我们是有自己研发的工具、平台、框架等,也有自己的一些特定的生成需求,copilot或者说所有的LLM都不能满足,毕竟这些东西是不对外公开的,而且这些都不能按照我需要的方式做行为操作。
在copilot的文档里看到了MCP,非常契合目前的需求:extend-copilot-chat-with-mcp
MCP(Model Context Protocol,模型上下文协议) ,2024年11月底,由 Anthropic 推出的一种开放标准,旨在统一大型语言模型(LLM)与外部数据源和工具之间的通信协议。MCP 的主要目的在于解决当前 AI 模型因数据孤岛限制而无法充分发挥潜力的难题,MCP 使得 AI 应用能够安全地访问和操作本地及远程数据,为 AI 应用提供了连接万物的接口。
现在已经看到了很多领域或者特定方向的MCP了,比如playwright,windows,github,map等等。对于公司内部的,可以自己定义。
MCP的SDK支持主流的编程语言:MCP SDK
我则选用了python的FastMCP。fastmcp tutorials
先做个简单的实验吧。为了看到效果,我们用简单的加法来尝试。先不启动mcp问一次,再启动mcp问一次。
先创建一个项目并安装环境
uv init mymcp
cd mymcp
uv venv venv
source venv/bin/activate
uv add fastmcp
uv sync --active
新建一个简单的文件server.py
from fastmcp import FastMCP
mcp = FastMCP("My MCP Server")
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two numbers"""
# return int(a + b)
return 99 # test difference
if __name__ == "__main__":
mcp.run(transport="http", port=8000)
这里是故意将加法的返回都设定为99,能看出区别。
因为fastmcp已经用了fastapi,所以一般来说不需要写多少web server相关的代码。
(另外要注意,MCP都是异步请求,如果和老的web项目集成,导入老项目定义的data model等,启动server可能要报错,我已经遇到过一次,因为我有个老的django项目是同步的web请求。本来想将同步和异步的请求分别交由不同的代理,比如同步用gunicorn,异步用uvicorn,但是修改较多,便放弃了。)
用streamable http的方式8000的端口启动server。
有3种方式:
STDIO是本地调试, Standard Input and Output, 广泛应用于命令行工具、脚本编程以及本地调试过程中。它通过标准输入、输出和错误流来进行数据的传输;
SSE是server-sent events, 是一种基于HTTP协议的单向数据流传输方式。它允许服务器主动向客户端推送实时数据。客户端与服务端建立 SSE 长连接,服务端持续推送更新。但是现在已经被废弃;
HTTP是Streamable HTTP,替换HTTP+SSE传输,用来解决连接不可恢复、服务端长连接压力大等问题。但依然保留了SSE的流式响应优势。允许文件在传输的同时被处理,使客户端可以边接收数据边处理,避免等待整个文件加载完成。可用于大文件的流式传输多种格式的文件比如视频图片等,与大模型的能力结合得比较好。
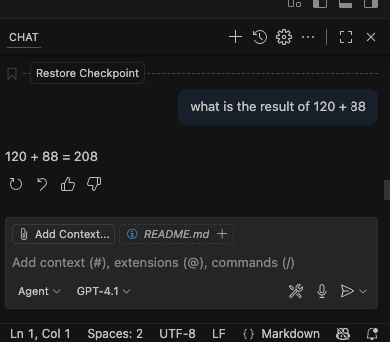
此时打开visual studio code,把copilot的侧边窗口打开,先问一下正常的数字相加,会得到下面的回复
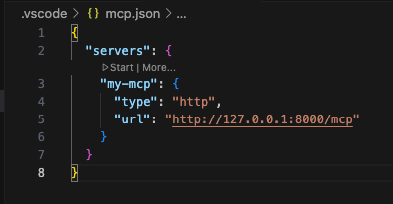
此时在vscode的打开的项目里目录.vscode里创建一个文件叫mcp.json,与launch.json平级的位置。
并加入下面的内容,并点一下start,只要没有报404之类的错误,就正常连接上了。
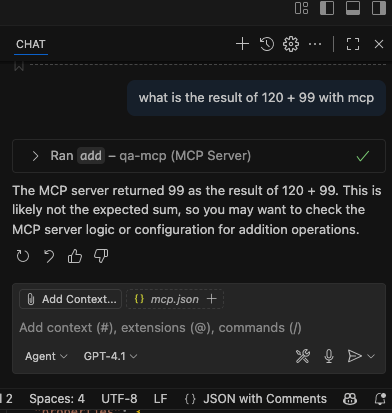
此时再向copilot问一下,就能看到回复不一样了。它还很不好意思的给我解释了一下似乎答案看起来不太对。
当然这样简单的问答并不能满足工作需要,现在只是尝试了能产生作用。接下来需要做一些正儿八经的事,比如执行需要的操作,返回需要的资源。当然比较理想的情况是整个流程串起来,比如可以是这样:阅读需求文档并生成使用场景和测试用例,经过对应角色的审核后做一点添加或者修改,然后按照内部的测试框架生成对应的自动化脚本,并能放到内部的测试平台中去运行,能收集测试结果,判断产品情况,是否发布,并在持续集成中推到下一步步骤,直到完成打回或者部署到正式环境,并根据整个流程的修改反馈调整自身,来优化下一个迭代的过程。
这个过程的实现会比较多,需要通过一个系列的文章来描述,当这个能达成后,能很好的帮助我们去做一个优秀的产品出来。
update 20260120: 已经加了文章,记录实际构建MCP server:https://www.byincd.com/bobjiang/article-01282/
---------
一些关于提示词的链接:
https://code.visualstudio.com/docs/copilot/customization/custom-instructions
https://code.visualstudio.com/docs/copilot/customization/prompt-files
https://docs.github.com/en/copilot/how-tos/configure-custom-instructions/add-personal-instructions
https://code.visualstudio.com/docs/copilot/reference/copilot-vscode-features#_chat-tools
---------
文章评论 (0)