前面介绍了用请求解析页面数据、headless加载页面js等资源的方式。我们也可以关注一下现有的轮子,一些比较优秀的爬虫框架。这里介绍一下scrapy,并以快速爬取网站全站的链接为例子说明。
scrapy是非常强大和方便的工具,它还提供了一些预设好的爬取类型。关于scrapy的组件可以参考下图,不做详细叙述。
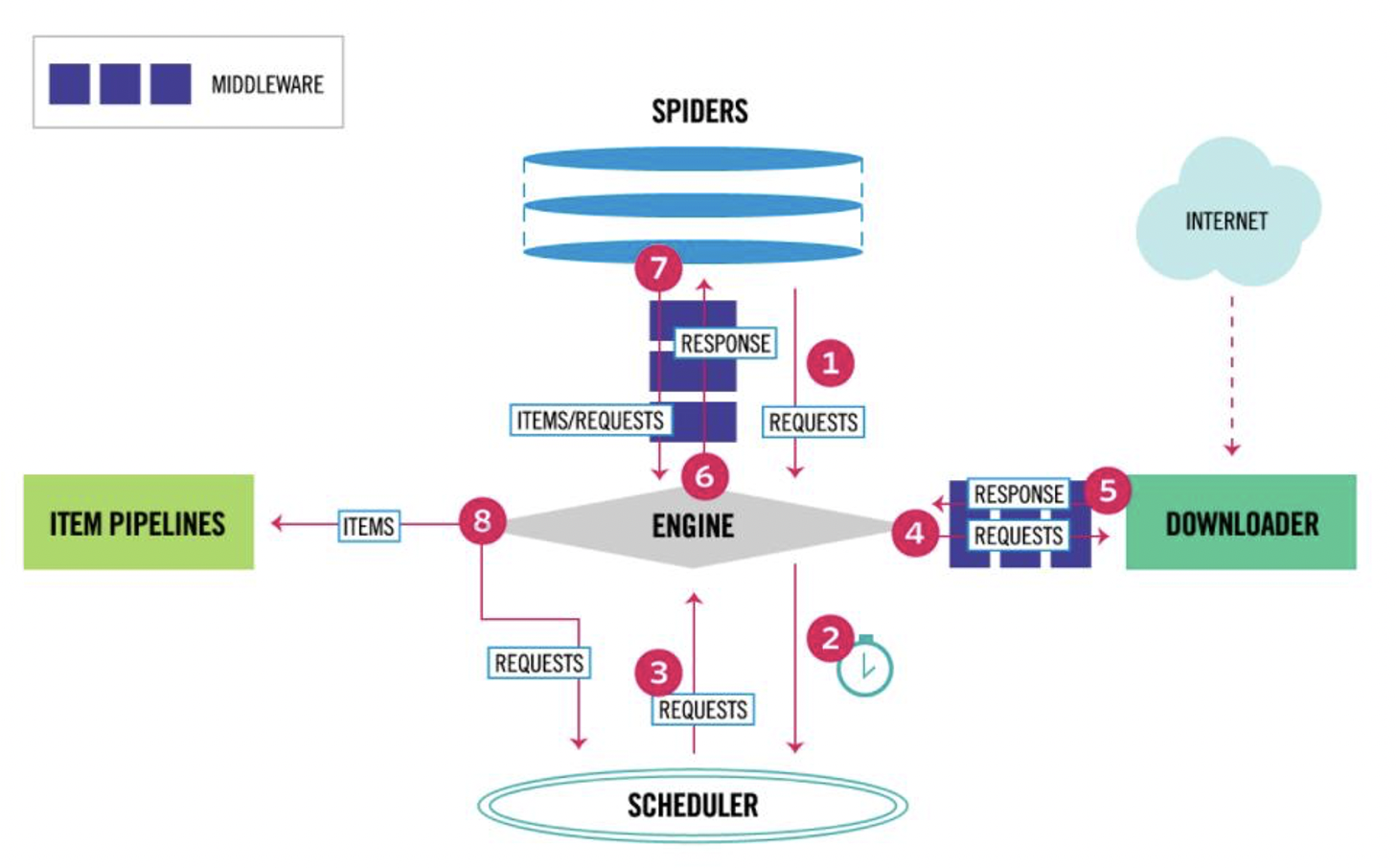
首先假设我们现在有一个需求,是爬取自己网站的所有链接,并检查是否存在404、500等状态的无效链接,来维护网站功能。
如果用requests之类的话,则需要设定非常多的规则,比如是否爬取重复链接因为有些页面的链接是一个循环,如何处理异常,解析什么样的类型的节点,等等。而scrapy已经有相应的处理了,我们只需要指定配置再设定自己的步骤就可以。
首先安装scrapy
pip install scrapy
然后启动一个项目
scrapy startproject myblog
此时已经自动生成了配置文件、中间件、爬虫的基本代码。
我们进入该目录
cd myblog
在spider文件夹中新增一个文件,这个文件则是我们具体要爬取的工作定义。
from pathlib import Path
import scrapy
class BlogSpider(scrapy.Spider):
name = "scrapy_blog"
allowed_domains = ["xxx.com"]
def start_requests(self):
urls = ["https://www.xxx.com/"]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = f'quotes-{page}.html'
Path(filename).write_bytes(response.body)
self.log(f'Saved file {filename}')
这是一个最简单的爬虫定义,我们指定允许的链接地址是xxx.com,开始爬行的链接定义在url这个列表中。要注意这个name的定义是命令行中需要对应上的名字。
此时运行一个简单的命令,便可看到当前目录下生成了一个文件记录了页面内容。
scrapy crawl scrapy_blog
但这肯定不够,没有满足我们的需要。于是需要改变一下。
首先我们继承的类不再是scrapy.Spider,改为CrawlSpider,这个类就是前面提到的预设了一些方便我们使用的方法,非常适合爬取全站。
与CrawlSpider合作的往往还有Rule和LinkExtractor,前者代表着爬取的行为规则定义,后者代表着我们爬取的是链接。
于是代码可以改为;
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class BlogSpider(CrawlSpider):
name = "scrapy_blog"
main_url = "xxx.com"
allowed_domains = ["xxx.com"]
start_urls = [f"https://{main_url}/"]
total = 0
rules = (
Rule(LinkExtractor(allow=(f".*{main_url}.*",)), callback='parse_item', follow=True),
)
def parse_item(self, response):
self.total += 1
res = {
"url": response.url,
"status": response.status,
"refer": bytes.decode(response.request.headers.get("Referer", "")),
"count": self.total
}
if response.status == 200:
self.log(f"valid: {res['url']}: {res['status']} -- {res['refer']}")
else:
self.log(f"valid: {res['url']}: {res['status']} -- {res['refer']}")
yield res
LinkExtractor(allow=(f".*{main_url}.*",))这里代表着抓取链接,但是必须符合这个正则的文本才会抓取。
callback='parse_item'这里代表着对于合适的对象采用parse_item这个方法做处理。
follow=True这里代表着递归爬取,链接可以跳转,就会随着跳转去下一个页面检查,相当于节省了我们很多功夫。(要注意的是,scrapy默认的设置是不会爬取重复的链接了,毕竟有些页面也会导向前一个页面或者主页。如果需要爬取重复的则需要设定dont_filter = False)
yield res则是将我们处理的信息返回,我们可以用来保存或者再处理。
在获取到链接进入到parse_item这个方法时,我们通过内部传递的reponse对象来取值具体的url、状态码、以及从header中获取从哪个页面跳过来的,这对于后续的记录很有用。
此时我们运行这个命令便可看到日志,如果指定-o的参数则可以将res保存到文件
scrapy crawl scrapy_blog # 看日志
scrapy crawl scrapy_blog -o links.json # 看到日志并且保存到links.json文件
但是在这里,会发现最终只爬取了200状态的链接,因为非200的被当做不正常状态被直接丢弃。因此我们需要在类里面加上一个配置:custom_settings = {'HTTPERROR_ALLOW_ALL': True},此时便可处理所有状态的链接。
另外如果不想用-o的参数来保存,还可以在spider文件中指定重写close方法。要么在parse_item方法中满足条件就保存文件,要么在close方法中在最后爬虫结束时保存文件。此时获取全站链接的爬虫代码便可以变成:
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class BlogSpider(CrawlSpider):
name = "scrapy_blog"
main_url = "xxx.com"
allowed_domains = ["xxx.com"]
start_urls = [f"https://{main_url}/"]
total = 0
custom_settings = {'HTTPERROR_ALLOW_ALL': True}
all_links = []
rules = (
Rule(LinkExtractor(allow=(f".*{main_url}.*",)), callback='parse_item', follow=True),
)
def parse_item(self, response):
self.total += 1
res = {
"url": response.url,
"status": response.status,
"refer": bytes.decode(response.request.headers.get("Referer", "")),
"count": self.total
}
self.all_liniks.append(res)
if response.status == 200:
self.log(f"valid: {res['url']}: {res['status']} -- {res['refer']}")
else:
self.log(f"valid: {res['url']}: {res['status']} -- {res['refer']}")
if self.total % 2000 == 0:
self.record_to_file()
yield res
def close(self, reason):
self.log("crawl end")
self.record_to_file()
def record_to_file():
with open("./links.csv", "w") as f:
for u in self.all_links:
url = u["url"]
url_from = u["refer"]
f.write(f"\"{url}\",{u['status']},\"{url_from}\"\n")
此时运行scrapy crawl scrapy_blog即可保存内容到文件。
如果想从其他文件来调取这个爬虫的话,则可以用到CrawlProcess,比如在根目录创建一个run.py:
from scrapy.crawler import CrawlerProcess
from myblog.myblog.spiders.blog_links import BlogSpider
if __name__ == "__main__":
p = CrawlerProcess()
p.crawl(BlogSpider)
p.start()
此时运行python run.py即可。
如果考虑到全站爬取的站点是一个包含很多内容的网站,需要爬取特别久,喂了以防特殊情况造成中断,需要一个能继续上一次爬取的功能,还好scrapy提供了这个功能,https://docs.scrapy.org/en/latest/topics/jobs.html
运行时指定-s,比如
scrapy crawl scrapy_blog -s JOBDIR=crawls_blog
或者在setting.py中设定
JOBDIR = 'PROJECT_DIR'
如果要同时展示log到console并且保存到文件,可以用下面这个命令
scrapy crawl scrapy_blog -s JOBDIR=crawls_blog 2>&1 | tee record_console.log
文章评论 (1)
如果被 connection refused 是哪里的问题