当对图像进行分类时,需要提供足够的样例图像并需要带有标签,这样在训练时才能知道什么样的图像特征对应到什么标签名,达到分类的目的。另外每次训练的损失度和准确率都有可能小幅浮动,属于正常现象。
官方keras有提供一些数据集,比如手写数字,比如该教程里用到的服装,图片是28x28并带有10种分类标签。
该教程是讲如何训练一个神经网络模型来为服装图片分类,比如衬衫、裤子、旅游鞋。
先引入工具包。
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib # mac上引用有报错所以需要指定一下qt5agg
matplotlib.use('qt5agg')
import matplotlib.pyplot as plt
载入服装数据集。
load_data会将数据拆分为训练集(60000)和测试集(10000),前者用来训练模型,后者用来检验模型。
这些图像都是28x28的numpy数组,带有0到255的像素值;标签则是从0到9的数组,代表着class_names里的一种类型名。
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
查看图像。
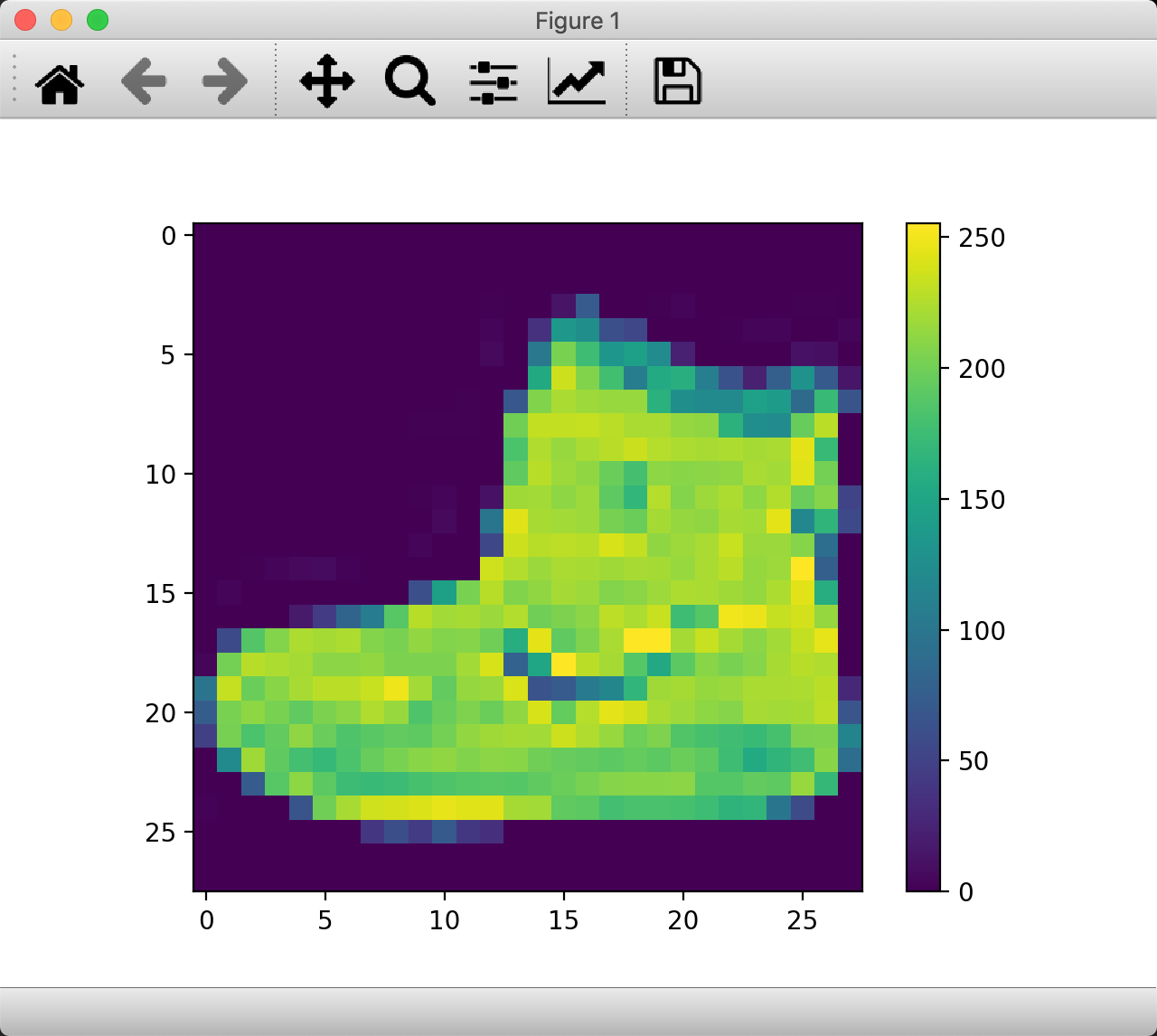
如果想查看图像,可以用matplotlib来展示。
plt.figure()
plt.imshow(train_images[0]) # 展示train_image的第一个图像
plt.colorbar()
plt.grid(False)
plt.show()
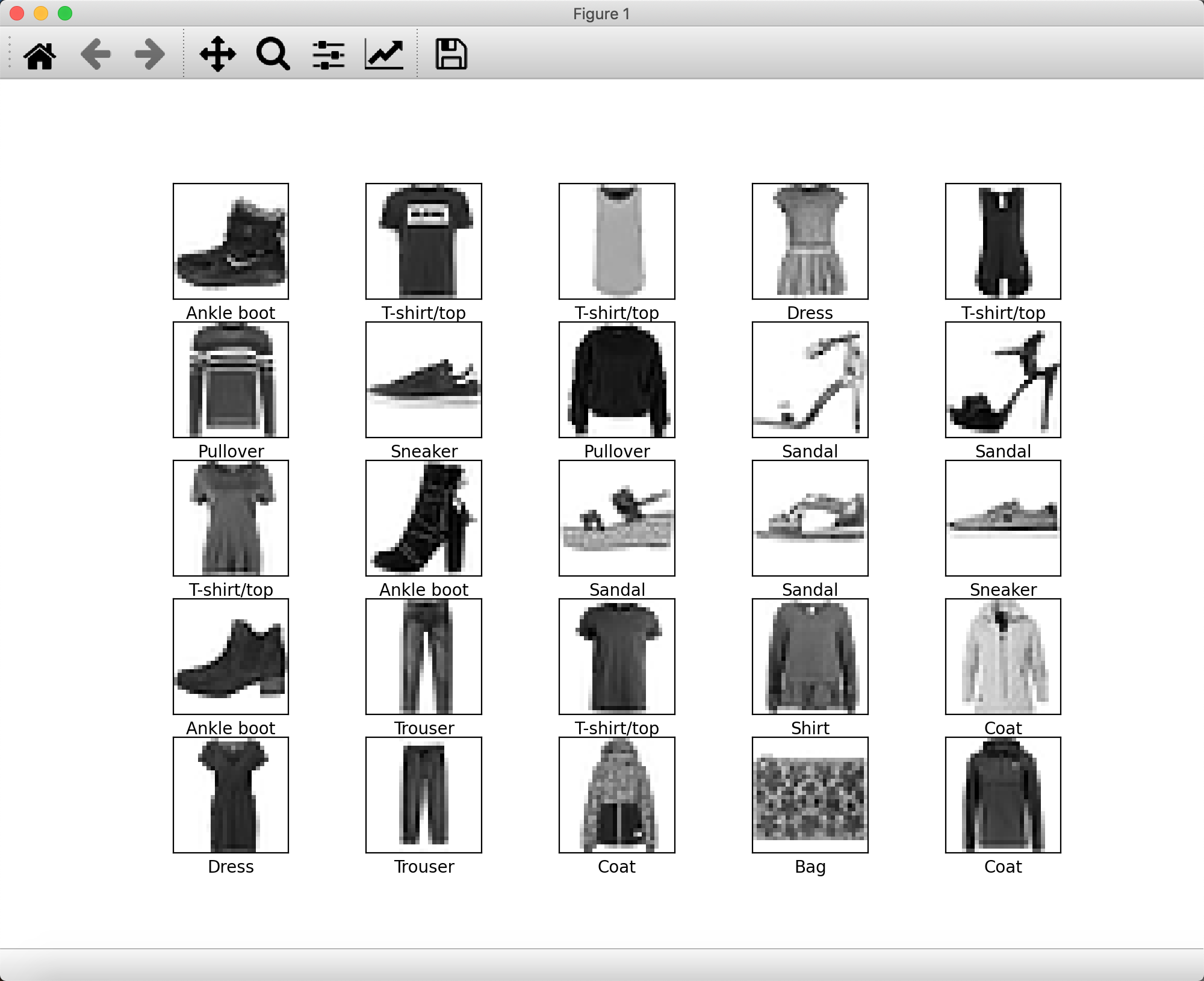
plt.figure(figsize=(10,10))
for i in range(25): # 展示25个图像
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()
数据归一化。
可以将像素值做归一化,这里是除以255,因为像素值是从0到255浮动。将像素值转换到0到1之间。
至于为什么需要做归一化,这是因为有些情况下有些特征向量中数值相差比较大,导致目标函数变扁平,不利于梯度下降,影响训练时间。并且归一化后有可能提高精度。比如knn里多种特征值,有的是0到10,有的是100到10000,不做归一化会导致计算的值的偏移。
当然在这里单个特征值不做归一化也可以训练。
train_images = train_images / 255.0
test_images = test_images / 255.0
构建模型-设置训练层
最基础的神经网络构建块就是层(layer),大多数的神经网络会把简单的layer链接在一起,多数layer类似tf.keras.layers.Dense需要指明一些参数。
我们这里训练用的模型类似如下:
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10)
])
第一层tf.keras.layers.Flatten会转换数据,将多维数组转换为单维数组。这一层没有参数用来学习,只是用来转换。
在此之后,该网络有两个连续的tf.keras.layers.Dense。他们被称为密集连接或者叫全连接的神经层。第一个Dense有128个节点(或者叫神经元),使用了relu这个激活函数;第二个则返回了数目为10的数组,每一个节点都会有一个分数来指明当前图像对应这10个类别的可能性。
编译模型。
在模型需要训练之前,它需要一些设定。
loss function:损失函数。它能衡量训练时当前的准确率,降得越低越好。
optimizer:优化器。它可以用于模型根据数据和损失函数来更新自己。
metrics:指标。用来监控训练时和测试时的步骤。这里用了accuracy来衡量被正确分类的图像比例。
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
训练模型。
训练神经网络模型需要如下步骤:
1. 将测试数据提供给模型。在这里时train_images和train_labels。
2. 模型将图像和标签联系起来。
3. 让模型对测试集进行预测,在这里时test_images。
4. 检验预测值是否符合实际的标签值,在这里时test_labels。
将数据提供给模型。
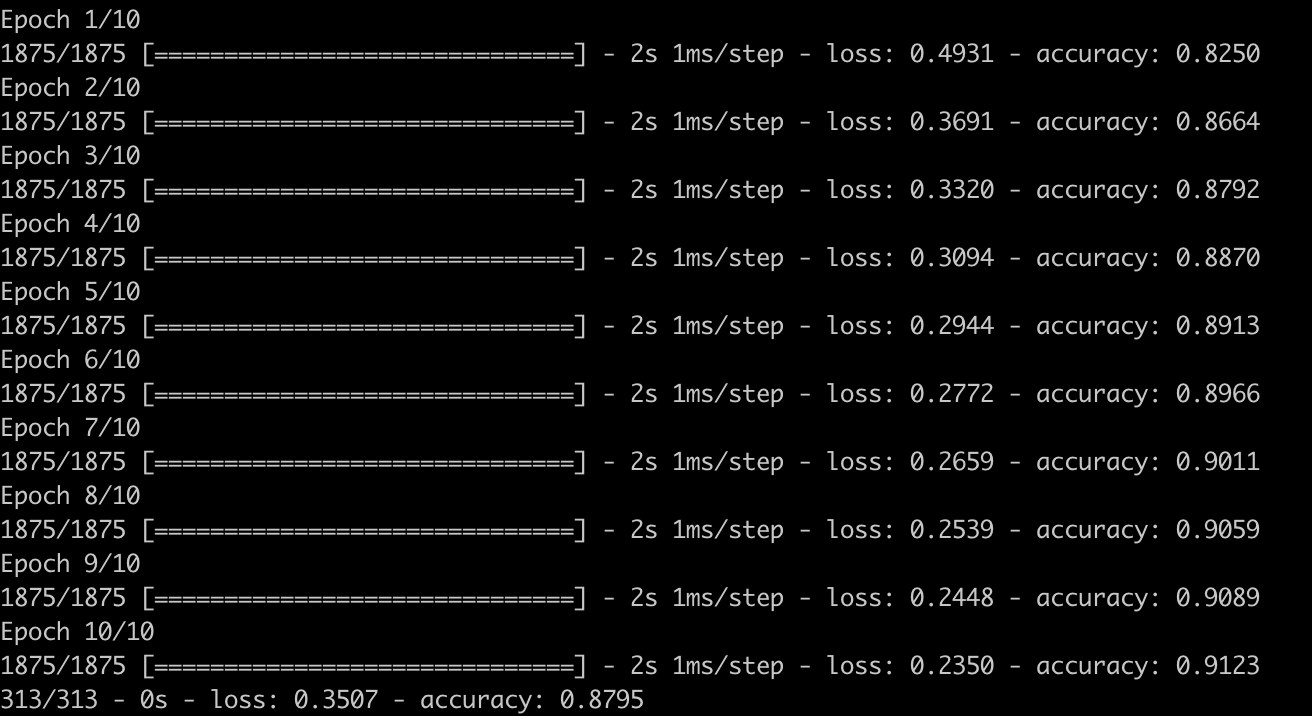
完成上述配置后,调用model.fit来训练。
model.fit(train_images, train_labels, epochs=10)
评估准确率。
用前面拆分出来的测试数据和测试标签来检验该模型以及评估准确率。
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
预测。
当模型训练完成后,我们就可以用它来对一些图像进行预测。
这里用softmax layer来将logits转换为概率值。(这里logits不好翻译,后续再来更新)
probability_model = tf.keras.Sequential([model, tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
所有测试图像的预测值就记录在predictions中了。
接下来检查到底预测为什么标签类型。
print(predictions[1]) # 第二个预测值的数组,对应着10个类别的概率
print(np.argmax(predictions[1])) # 最大的预测值
print("the predict label is: ", class_names[np.argmax(predictions[1])]) # 预测的标签类型
print("the actual label is: ", class_names[test_labels[1]]) # 实际的标签类型
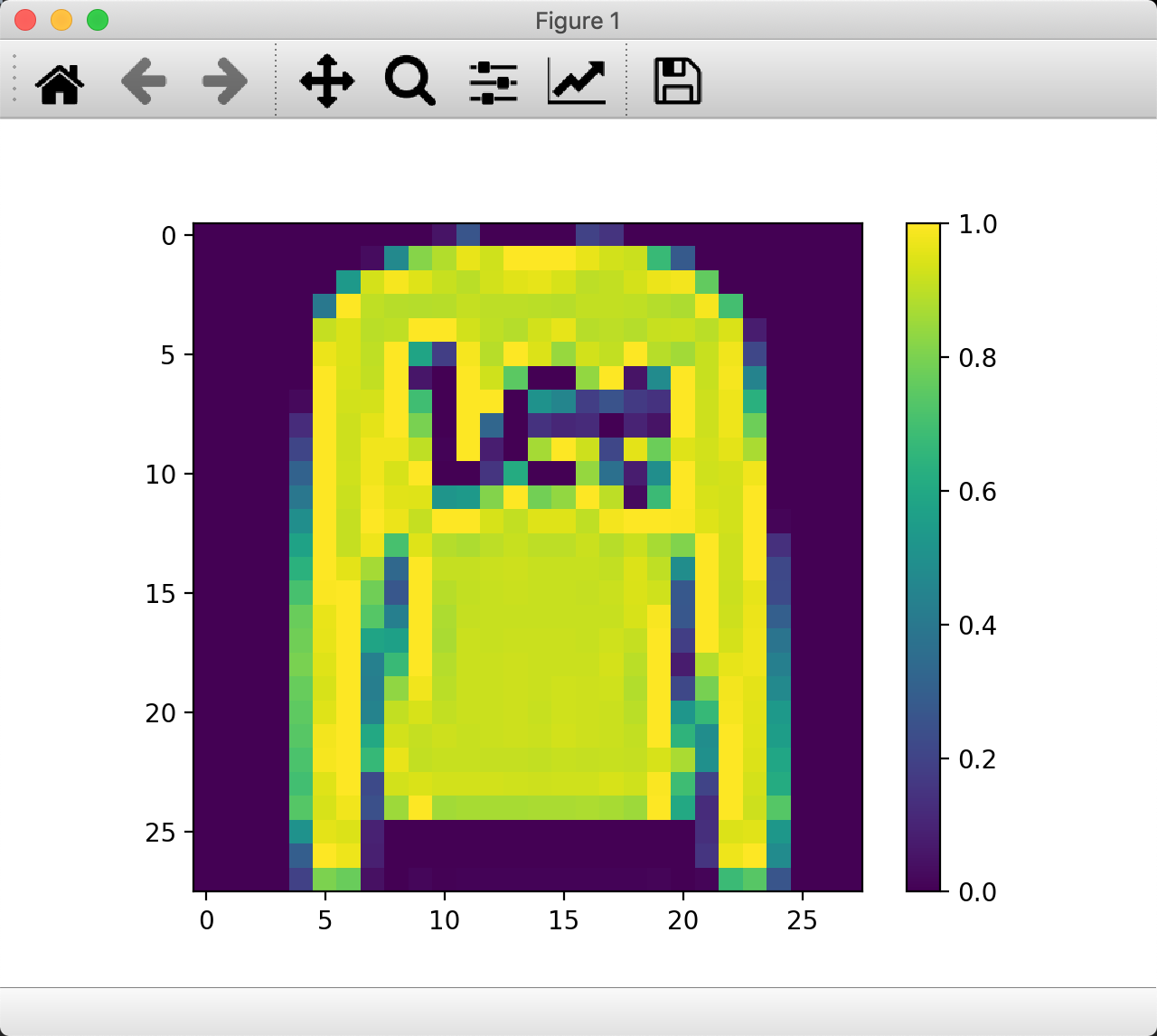
plt.figure() # 这里展示
plt.imshow(test_images[1])
plt.colorbar()
plt.grid(False)
plt.show()
也可以让预测的标签和概率显示在图表上。
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array, true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
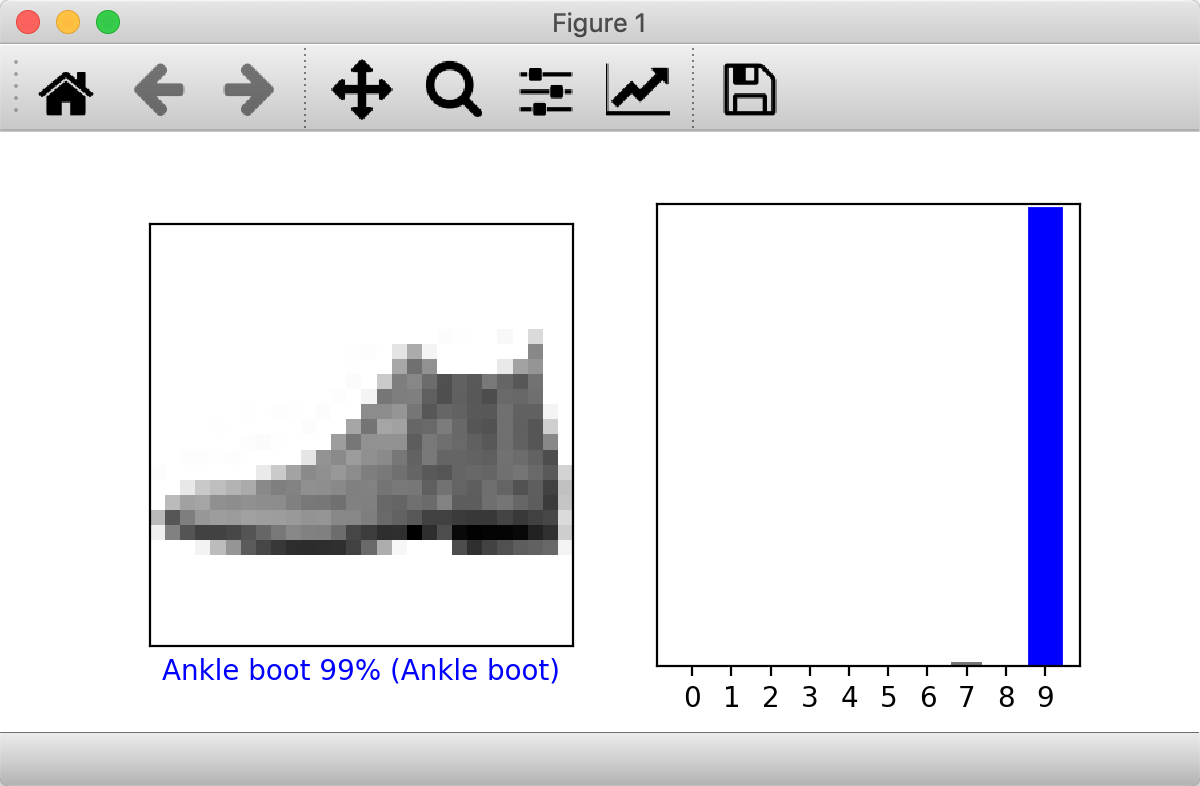
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array, true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
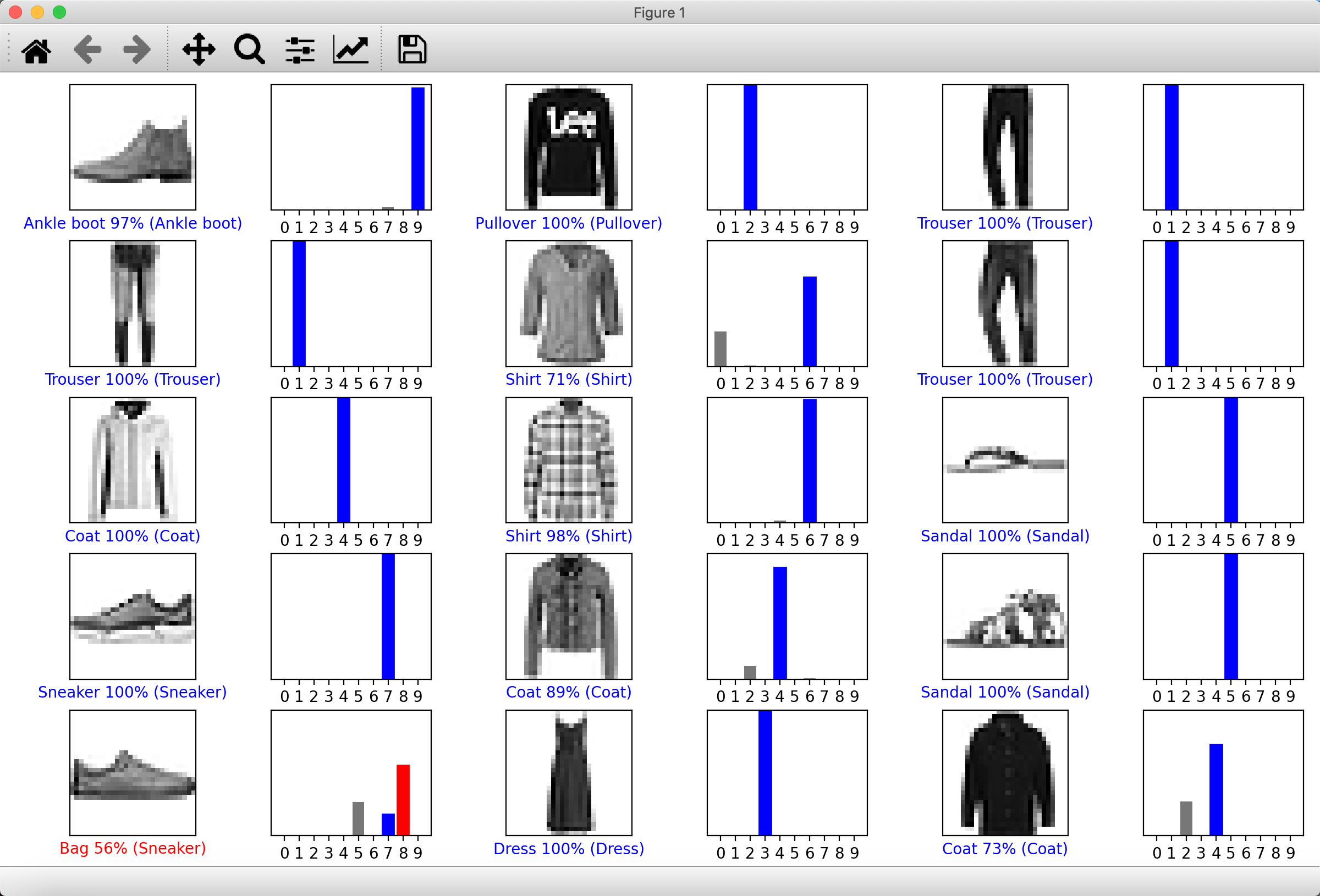
展示多个图像的预测标签。
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()
官方原文地址:https://www.tensorflow.org/tutorials/keras/classification
文章评论 (0)